Problem of The Day: Maximum Profit in Job Scheduling
Problem Statement
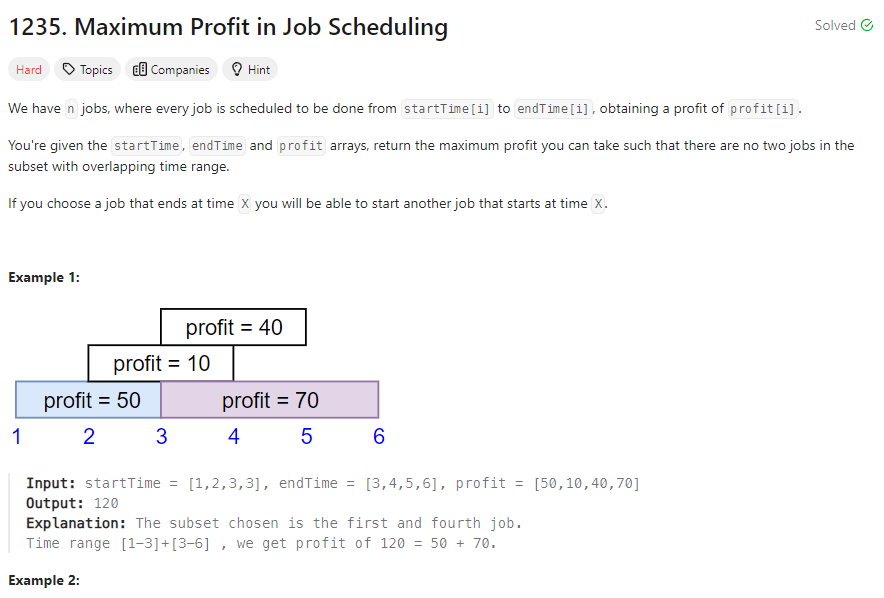
See more details.
Intuition
My initial thought is to consider all possible combinations of jobs to maximize the profit. Sorting the jobs by their end times helps in traversing them in chronological order.
Approach
I create a list of jobs by zipping the start times, end times, and profits. I then sort this list based on end times. The dfs function is a recursive function that explores all possible combinations of jobs. It takes an index and the current profit as parameters.
Inside the dfs function, I get the current job’s start time, end time, and profit. I update the current profit by adding the profit of the current job. The global variable dfs.result keeps track of the maximum profit encountered during the exploration.
I iterate over the remaining jobs, and if the start time of a job is greater than or equal to the end time of the current job, I recursively call the dfs function for that job.
Complexity
-
Time complexity: The time complexity is exponential, as the algorithm explores all possible combinations of jobs.
-
Space complexity: The space complexity is also high due to the recursive calls and the storage of intermediate results.
Brute Force Code
# TIME LIMIT EXCEEDED
class Solution:
def jobScheduling(self, startTime: List[int], endTime: List[int], profit: List[int]) -> int:
temp = []
N = len(profit)
jobs = sorted(zip(startTime, endTime, profit), key=lambda x: x[1])
@lru_cache(maxsize=None)
def dfs(index, curr_profit):
cstart, cend, cprofit = jobs[index]
curr_profit += cprofit
dfs.result = max(dfs.result, curr_profit)
for i in range(index + 1, N):
nstart, nend, nprofit = jobs[i]
if nstart >= cend:
dfs(i, curr_profit)
dfs.result = 0
for i in range(len(profit)):
dfs(i, 0)
return dfs.result
Improved Code
To improve the brute force solution above, I read through editorial solution and learned that I could use the Binary search and memorization to reduce the search space. It helped me to bypass the hard limit on Leet Code submission. Here is my intuition and approach to improve the solution.
Intuition
My thought is to employ a dynamic programming approach to optimize the solution. Sorting the jobs by their start times allows for a chronological traversal. The dfs function explores all possible combinations of jobs while keeping track of the maximum profit.
Approach
I first create a list of jobs by zipping the start times, end times, and profits. This list is then sorted based on start times. The binary_search_left function efficiently finds the next job index whose start time is greater than or equal to the current job’s end time.
The dfs function is a recursive approach that explores the combinations of jobs. It considers both skipping the current job (skip) and taking the current job (take). The result is the maximum profit encountered during the exploration.
Complexity
-
Time complexity: The time complexity is improved compared to the brute force approach due to dynamic programming. The function avoids redundant calculations by using memoization. The time complexity is still influenced by the binary search operation, making it approximately O(n log n).
-
Space complexity: The space complexity is controlled through memoization, which stores intermediate results. It is O(n) where n is the number of jobs.
Code
class Solution:
def jobScheduling(self, startTime: List[int], endTime: List[int], profit: List[int]) -> int:
# Create a list of jobs by zipping start times, end times, and profits and sorting by start times
jobs = sorted(zip(startTime, endTime, profit), key=lambda x: x[0])
# Extract sorted start times for efficient binary search
sorted_startTime = [st for st, _, _ in jobs]
def binary_search_left(sorted_startTime, curr_end):
# Perform binary search to find the next job index whose start time is greater than or equal to curr_end
left, right = 0, len(sorted_startTime) - 1
next_index = len(sorted_startTime) # Set to maximum to avoid exceeding recursion depth
while left <= right:
mid = left + (right - left) // 2
if sorted_startTime[mid] >= curr_end:
next_index = mid
right = mid - 1
else:
left = mid + 1
return next_index
def dfs(index, memo, jobs, sorted_startTime):
if index == N:
return 0
if index in memo:
return memo[index]
curr_start, curr_end, curr_profit = jobs[index]
# Explore both skipping and taking the current job
next_index = binary_search_left(sorted_startTime, curr_end)
skip = dfs(index + 1, memo, jobs, sorted_startTime)
take = dfs(next_index, memo, jobs, sorted_startTime) + curr_profit
# Calculate and memoize the maximum profit
max_profit = max(skip, take)
memo[index] = max_profit
return max_profit
# Initialize memoization dictionary and start the recursive exploration
memo = defaultdict(int)
return dfs(0, memo, jobs, sorted_startTime)
Editorial Solution
Bottom-Up Dynamic Programming + Binary Search
class Solution {
public:
// maximum number of jobs are 50000
int memo[50001];
int findMaxProfit(vector<int>& startTime, vector<vector<int>>& jobs) {
int length = startTime.size();
for (int position = length - 1; position >= 0; position--) {
// it is the profit made by scheduling the current job
int currProfit = 0;
// nextIndex is the index of next non-conflicting job
// this step is similar to the binary search as in the java solution
// lower_bound will return the iterator to the first element which is
// equal to or greater than the element at `jobs[position][1]`
int nextIndex = lower_bound(startTime.begin(), startTime.end(), jobs[position][1]) - startTime.begin();
// if there is a non-conflicting job possible add it's profit
// else just consider the curent job profit
if (nextIndex != length) {
currProfit = jobs[position][2] + memo[nextIndex];
} else {
currProfit = jobs[position][2];
}
// storing the maximum profit we can achieve by scheduling
// non - conflicting jobs from index i to the end of array
if (position == length - 1) {
memo[position] = currProfit;
} else {
memo[position] = max(currProfit, memo[position + 1]);
}
}
return memo[0];
}
int jobScheduling(vector<int>& startTime, vector<int>& endTime, vector<int>& profit) {
vector<vector<int>> jobs;
// storing job's details into one list
// this will help in sorting the jobs while maintaining the other parameters
for (int i = 0; i < profit.size(); i++) {
jobs.push_back({startTime[i], endTime[i], profit[i]});
}
sort(jobs.begin(), jobs.end());
// binary search will be used in startTime so store it as separate list
for (int i = 0; i < profit.size(); i++) {
startTime[i] = jobs[i][0];
}
return findMaxProfit(startTime, jobs);
}
};
Python Solution from discussion/forum
class Solution:
def jobScheduling(self, startTime: List[int], endTime: List[int], profit: List[int]) -> int:
start, end, p = 0, 1, 2
jobs = list(zip(startTime, endTime, profit))
jobs.sort(key=lambda x: x[start])
N = len(jobs)
dp = [0] * (N + 1)
for i in reversed(range(N)):
nxt = bisect.bisect_left(jobs, jobs[i][end], key=lambda x: x[start])
dp[i] = max(jobs[i][p] + dp[nxt], dp[i + 1])
return dp[0]